スターレイルのIME辞書を作ろうとして、結果的に自動で辞書を作るアプリケーションを作った話

ゲーム「崩壊:スターレイル」をプレイしていると、キャラクター名やスキル名、地名など、独特な固有名詞が数多く登場します。これらの用語をPCの辞書(IME)に登録しておくと、ブログ記事の執筆やSNSでの投稿が非常にスムーズになります。
今回は、Cloudflareの無料枠をフル活用して、Web上の情報を自動的にクロールし、LLMで用語を抽出・分類するシステムを構築しました。
試行錯誤の経緯
1. 手動での作成を断念
最初は手動で辞書を作成することを検討しましたが、用語数の多さとメンテナンスコストの高さから、検討段階で早々に諦めました。自動化が必須だと判断し、次のアプローチへ移りました。
2. Python + 形態素解析アプローチ
次に、Pythonでクローラーと形態素解析を実装し、フロントエンドのみCloudflareで動かす構成を試みました。一旦実装は完了したものの、以下の問題に直面しました。
形態素解析の限界
- 独自用語が多すぎて、形態素解析が役に立たない
- 切って欲しくないところで切ってしまう
- 切って欲しいところで切ってくれない
- 「」や:、""などのルールベース処理が増え、破綻が見えていた
コストの問題
- GitHub Actionsでクローラーと形態素解析を動かすと無料枠では厳しい
- 辞書 → 形態素解析 → 辞書 の改善ループを回すのが困難
Cloudflareとの相性
- D2のmigrationや仕様が通常のSQLiteと異なり、ローカルとの同期が難しい
- Python側とCloudflare側でスキーマの互換性を維持するのが困難
これらの理由から、このアプローチも断念しました。
3. Cloudflareオンリー構成
新しいプロダクトと新しい技術を同時に採用するのは本来避けたいところですが、他に選択肢がなかったため、Cloudflare完結型の構成に踏み切りました。
形態素解析がCloudflareで実現困難だったため、Cloudflare Workers AIを使った用語抽出に切り替えました。
Cloudflareの利点
- Queueがある: スケールが非常に楽
- コストが安い: 無料枠が大きく、個人プロジェクトに最適
- Terraform Provider: IaCで管理できる
- 豊富なコンポーネント: Workers AI、Queue、Zero Trust、Observability、MCPなど
Cloudflareの課題
- バッチ処理がない: 大量処理の設計に工夫が必要
- ローカル開発が複雑: 開発環境の構築にやや手間がかかる
- 制約の強さ: WorkersやD2の特性に、アプリケーション仕様が強く制約される
システムの目的
- 自動収集: Webサイトを自動的に巡回し、最新の情報を収集
- 用語抽出: 収集した本文からLLMを使用して用語・読み仮名・カテゴリを抽出
- 一般用語フィルタ: 一般用語を専門用語から自動除外
- 配布: Google日本語入力、macOS、MS-IMEなどの各形式でダウンロード提供
アーキテクチャ概要
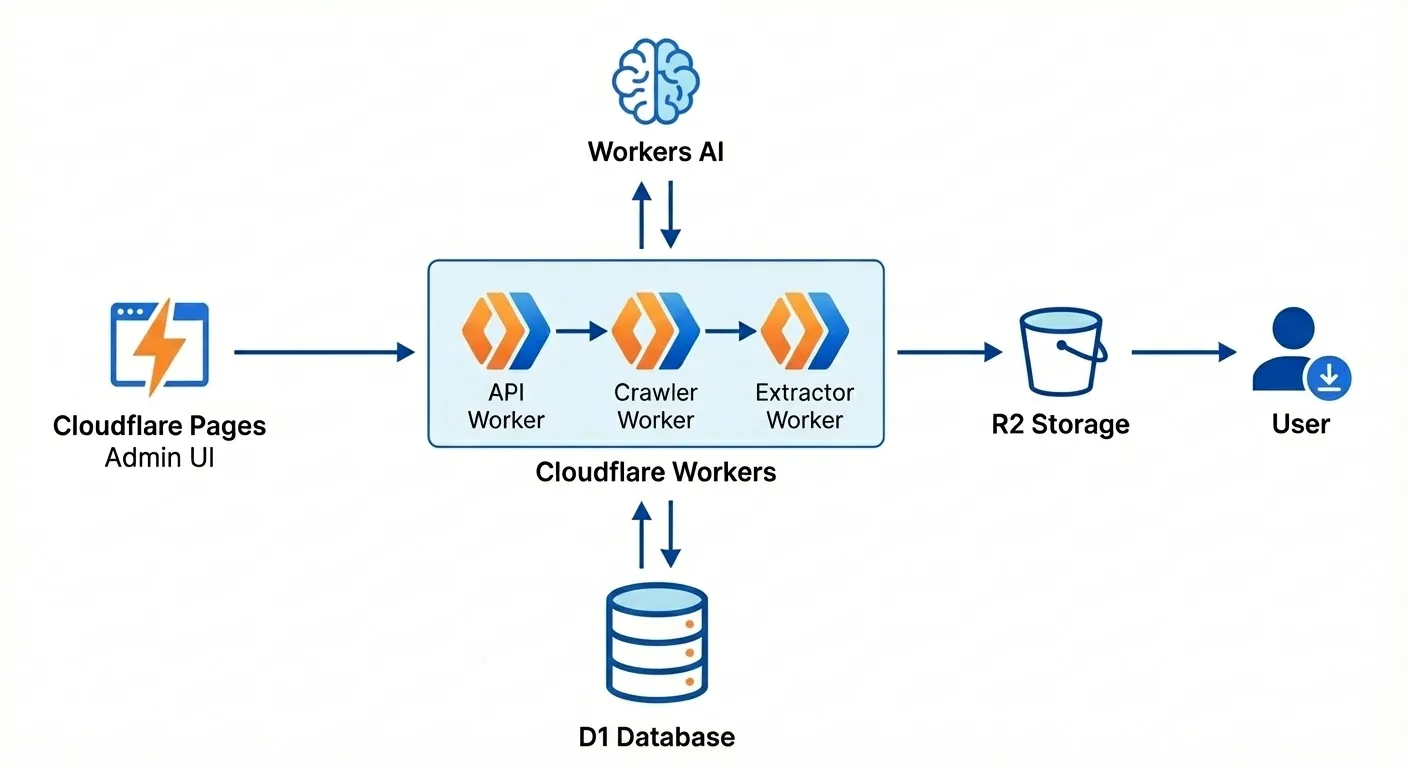
処理フロー
Cron Trigger (1日1回)
↓
API Worker (scheduled handler で対象URL取得)
↓
Crawl Queue
↓
Crawler Worker (HTML取得 → 本文抽出 → 2000文字/チャンクで分割)
↓
Extract Queue
↓
Extractor Worker (Workers AI で用語抽出 → Mozc辞書フィルタ)
↓
D1 Database (用語保存)
↓
管理UI (最終確認・ラベリング)
↓
R2 Storage (IME辞書ファイル配信)クローリングアルゴリズム
**BFS(幅優先探索)**を採用しています。Webサイトをグラフとして捉え、シードURL(トップページ)から順に探索します。
- 重要なページはシードに近い傾向がある
- 途中で止めてもカバレッジが良い
- Queueを使うと自然にBFSになる
Cloudflare QueuesのFIFO特性により、追加実装なしでBFSが実現できます。
Workersの役割
API Worker(Scheduler機能含む)
- HTTP API: 管理UIとのインターフェース、用語の検索・編集・分類
- Cronトリガー(1日1回): D1から未処理のURLを取得し、Crawl Queueに投入
- IME辞書のエクスポート(R2へのアップロード)
- ダウンロード統計の記録
Crawler Worker
- Crawl QueueからURLを受信
- HTMLを取得(@mozilla/readability + linkedom で本文抽出)
- リンクを抽出してD1に登録(BFSの次の層)
- 本文を2,000文字ごとにチャンク分割
- 各チャンクをExtract Queueに投入
レート制限:
- Queueの
max_batch_sizeとmax_concurrencyで同時実行数を制御 - 外部サイトに負荷をかけないよう、適切な間隔で処理
Extractor Worker
- Extract QueueからチャンクとページIDを受信
- Workers AIで用語抽出
- 抽出された用語をD1に保存(upsert)
- Mozc辞書フィルタを適用
- 分類情報(specialized/common/meta)を保存
エラーハンドリング:
- パース失敗時は空配列を返してスキップ
- 失敗したメッセージはリトライキューに再投入
LLMによる用語抽出 (Workers AI)
抽出された本文から用語を取り出すのは、Cloudflare Workers AIを使用しています。現在は @cf/openai/gpt-oss-20b をデフォルトモデルとして採用しています。
モデル選定の経緯
当初はMistralやLlama-3.xを試しましたが、結果が不安定で、特に簡単な読み仮名でも大量に間違えることがありました。GPT-OSS-20Bに切り替えたところ、精度が大幅に向上しました。
コスト試算
Cloudflare Workers AIの無料枠は10,000 neurons/日です。neuronsの消費量はモデルやリクエスト内容により異なりますが、実運用では1チャンク(約2,000文字)あたり数〜数十neuronsを消費します。
無料枠の10,000 neuronsで処理できる目安:
- LLMレスポンス生成: 約130回
- 画像分類: 約830回
- 埋め込み生成: 約1,250回
Cronで1日1回実行し、1回あたり数十ページをクロールする運用であれば、無料枠内で十分に運用可能です。
プロンプト設計
LLMには以下のようなシステムプロンプトを与えています:
抽出対象:
- キャラクター名(例: キュレネ、ホタル、銀狼)
- スキル名・必殺技名(例: 愛と明日へ向かって♪)
- ステータス・属性名(例: 氷属性、会心ダメージ)
- ゲームシステム用語(例: 運命、軌跡、光円錐)
- 地名・組織名(例: ピノコニー、エリュシオン)
- 敵・ボス名、バフ・デバフ名
除外対象:
- 一般的な日本語(こと、もの、ため、など)
- Wiki操作用語(編集、コメント、ページなど)
- 括弧付き表記(「疑似花萼(金)」→ 「疑似花萼」のみ抽出)
- アルファベット混合のステータス用語(HP、SP、EPなど)
出力形式:
{
"terms": [
{
"text": "用語",
"reading": "よみがな",
"termType": "character|skill|status|system|item|location|enemy|buff",
"classification": "meta|common|specialized"
}
]
}termType(用語の種類):
character: キャラクター名skill: スキル名・必殺技名status: ステータス・属性名system: ゲームシステム用語item: アイテム・素材名location: 地名・組織名enemy: 敵・ボス名buff: バフ・デバフ名
classification(IME辞書用の分類):
specialized: 専門用語(IME辞書に含める)common: 一般用語(IME辞書に含めない)meta: メタ情報(IME辞書に含めない)
LLMを使うメリット
従来の形態素解析やキーワード抽出と異なり、LLMは以下を同時に推論できます:
- 用語の抽出: 文脈から専門用語を識別
- 読み仮名の生成: 独自の固有名詞でも適切な読みを推定
- カテゴリ分類: キャラクター、スキル、地名などの自動分類
これにより、後処理のルールを大幅に削減でき、メンテナンス性が向上しました。
一般用語のフィルタリング
LLMは時として「攻撃」や「防御」といった一般的な単語も「専門用語」として抽出してしまいます。これを防ぐために、一般用語辞書を使った自動フィルタリングの仕組みを導入しました。
Mozc辞書の活用
Google日本語入力のオープンソース版であるMozcの辞書データを活用しています。Mozcの辞書データは以下の2つのソースから構成されています:
- IPAdic (奈良先端科学技術大学院大学): 使用・複製・配布が許可されている
- Okinawa Dictionary: パブリックドメイン
これらの辞書に含まれている単語は「一般的に変換可能な用語」と判断し、専門用語から除外します。
フィルタリングのロジック
LLMが専門用語(specialized)と判定
↓
Mozc辞書で完全一致検索
↓
存在する → 一般用語(common/rule) に再分類
存在しない → 専門用語(specialized/llm) のまま重要な仕様:
- 完全一致のみ: 部分一致は行わない(「流」があっても「鏡流」は専門用語として扱う)
- specializedのみ変換: LLMが既に
commonやmetaと判定したものは変換しない - 手動分類を保護: 管理UIで手動分類した用語は上書きしない
この仕組みにより、「攻撃」「防御」などの一般用語がIME辞書に含まれることを防ぎつつ、「銀狼」「鏡流」などのキャラ名は正しく抽出できます。
IME辞書のエクスポート
抽出された用語は、管理UIで最終確認・ラベリングを行った後、各IMEが読み込める形式でR2ストレージに保存され、CDN経由で配信されます。
| 形式 | 対象OS | ファイル形式 |
|---|---|---|
| Google日本語入力 | Windows / Mac / Linux | 読み\t単語\t固有名詞 (UTF-8) |
| macOS標準 | Mac | 読み\t単語 (UTF-8) |
| MS-IME | Windows | 読み\t単語\t固有名詞 (UTF-16LE + BOM, CRLF) |
認証とセキュリティ
セキュリティ面では、Cloudflareのサービスを組み合わせてシンプルかつ堅牢な構成を実現しています。
- Admin UI: Cloudflare Zero Trust Accessで保護し、認証されたユーザーのみアクセス可能
- Worker間通信: サービス内での通信のみを許可し、外部からの直接アクセスを遮断
Cloudflareを本格的に使うのは初めてで、従来のクラウドIaaSとは勝手が異なることに戸惑いましたが、結果的にはほぼ内部のみで通信を完結する、シンプルなアーキテクチャを構築できました。
まとめ
Cloudflareのサーバーレス基盤を組み合わせることで、実質ランニングコストほぼゼロで、LLMを活用した高度な自動収集システムを構築できました。
コストの内訳(無料枠内で運用)
| サービス | 無料枠 | 使用量(目安) |
|---|---|---|
| Workers | 100,000リクエスト/日 | ~1,000リクエスト/日 |
| Workers AI | 10,000 neurons/日 | モデルにより変動 |
| D1 | 500万行読み取り/日 | ~10万行/日 |
| R2 | 10GB, 1000万Class B操作/月 | ~1GB, ~1万読み取り/月 |
| Queue | 10,000操作/日 | ~1,000操作/日 |
1日1回のCron実行、数十ページのクロールであれば、すべて無料枠内で運用できます。
技術的なポイント
- Queue駆動のアーキテクチャ: Cron → Queue → Worker の非同期処理でRate Limitを回避
- LLMによる自動抽出: Workers AIを活用し、用語・読み・カテゴリを効率的に抽出
- 一般用語フィルタ: Mozc辞書による自動除外でIME辞書の品質を確保
- BFSアルゴリズム: 重要なページから優先的にクロール
ゲームのアップデートごとに手動で辞書を更新するのは大変ですが、このように自動化することで、常に最新の用語集をユーザーに提供し続けることが可能になります。